CSS Forums
Sunday, April 28, 2024
12:06 PM (GMT +5)
12:06 PM (GMT +5)





|
#1
 Monday, April 11, 2005
Monday, April 11, 2005
|
||||
|
||||
|
First what is LAN means Local Area Network?
This type of network is mostly used in one building and in which the connected computers are not more than 256. A LAN connects network devices over a relatively short distance. A networked office building, school, or home usually contains a single LAN, though sometimes one building will contain a few small LANs, and occasionally a LAN will span a group of nearby buildings. In IP networking, one can conceive of a LAN as a single IP subnet (though this is not necessarily true in practice). Besides operating in a limited space, LANs include several other distinctive features. LANs are typically owned, controlled, and managed by a single person or organization. They also use certain specific connectivity technologies, primarily Ethernet and Token Ring. The distinction between a LAN and a WAN involves the physical distance that the network spans. A third category, the MAN, also fit into this scheme as it too is centered on a distance-based concept. What the topology is:- the way in which connections are made and arrangement of computer is referred as topology. Two kinds of Topologies are: Physical and Logical. Physical topologies are bus, star , ring and physical mesh topology. Bus:- in this type of topology the computers are connected by a single cable and we use terminator at the end of the cable that is used to bounce back the signal. In which we have the logical topology Ethernet 10 Base 2. Repeaters are used in the place of Hubs. Star:- the computers are arranged in the form of star and in which we have a central hub . the logical topology that works here is Ethernet 10 Base 5. trouble shooting is easy in star just bcoz of Hub. Ring:- when we need high performance network we use ring topology in which computers are arranged in form of ring . it is an expensive one . we use token passing method in this topology . logical topology is FDDI(Fiber Distributed Data Interface). Physical Mesh Topology: combination of different topologies. Most expensive topology provides MAN: A Metropolitan Area Network connects an area larger than a LAN but smaller than a WAN, such as a city, with dedicated or high-performance hardware. For example: if we have network b/w Rawalpindi and Islamabad or Karachi and Hyderabad then it is dubbed as MAN. WAN(Wide Area Network): A wide-area network spans a large physical distance. A WAN like the Internet spans most of the world! A WAN is a geographically-dispersed collection of LANs. A network device called a router connects LANs to a WAN. In IP networking, the router maintains both a LAN address and a WAN address. WANs differ from LANs in several important ways. Like the Internet, most WANs are not owned by any one organization but rather exist under collective or distributed ownership and management. WANs use technology like ATM, Frame Relay and X.25 for connectivity. WAN requires special media , which are provided by telephone companies. WAN also requires special hardware. Physical media for WAN: WANs use special purpose telephone wires, fiber optic cables, microwaves or satellites for communication. The simplest WANs use dedicated lines, which are special conditioned telephone lines that directly and permanently connects two computers. Microwaves are radio waves that have a very high frequency .the disadvantage of using them is that they depend on line of sight transmission. No obstruction can get in the way, and they can travel only about 50 miles. Communication satellites are placed in geosynchronous orbit thousands of miles above the earth. In this orbit, the satellite rotates with the earth so that it is always above a given spot. The latest WANs use long distance fiber optic cables. WAN uses some special hardware items and these are multiplexor(combines input signals from several computers and sends the combines signal along the communication channel) routers(they receive packets of data and examine their address, they decide where to send each packet) , front-end processors(handle all the communications tasks for large computers, and also provide security to prevent unauthorized access). This is what the WAN , I discussed WAN in detail as compare to MAN, bcoz if you have good understanding of LAN and WAN , you can easily understand MAN as it is stuck between LAN and WAN.. the only difference is of distance. Entity Relationship model is a logical representation of data of an organization or a business area.As visible from its name, it's about the relationship between certain entities which are logically related.What is an entity?Entity is about(the description of) a person, an object, place or an event or even concept in the user environment about which an organization may wish to organize data.Where there is a name of "Relationship", it is obvious that this is a term belongs to the RDBMS(Relational Database Management System).And as we know that in this kind of DBMS we develop relations between two similar kind of entitiy instances which may posses (conditionally)different attributes('Charecteristics of an entity type which may be an interest of an organization') but must represent a common objective.Attributes have three primary types;Simple,Multivalued and Derived.Another term used quite fluently in E-R model is Instance or Entity Instance. Instance is the occurance of an entity type.And is necessary to bring into notice before creating any sort of E-relationship is made.That was a brief introduction to Entity and terms linked to it. Now what is a relationship?It is a binding factor which associates two or more (instances of)entity types together to form a smart Database which will be helpful for user(easily modified or updated) as well as for the MIS and DSS (to get information whenever needed in a detailed fashion).What happens when a relationship is created?Relationship acts like a glue to the entities to join them together.Or should I illustrate it more meaningfully as:"Relationship is an association among the instances of one or more than one entity types". Here Part-I "introduction to Entity, Relationship and E-R Model" finishes here.In the next part I will describe how an E-R model is developed and what are different kinds of E-R models. Part-II "Constructs of an E-R model and Types of relationships " While constructing an E-R Model one should have good acquaintance with the cardinal constraints. A constraint which specifies the number of the instances of an entity type for example B which may associate with another called A.It specifies minimum and maximum no of instances of an entity type.Possible constraints are Mandatory one,Mandatory many,optional one ,optional many and a specific no.A minimum cardinality of 0 specifies optional participation while 1 represents mandatory. Relationships are of three types in general.Unary(relationship between the single entity type's instances);Binary(relationship between the instances of two entity types);Ternary(relationship between the instances of three entity types). Degree is the number of entity types which participate in a relationship.(Unary;1,Binary;2 and Ternary;3). In unary type of relationship there may be one-to-one or one-to-many relations. In Binary type there may all the three major kinds involved;one-to-one,one-to-many and many-to-many(instances of entity type). In ternary a simultaneous relationship between three different entity types('s instances)takes place. Another thing which I want to mention here is the two types of entities.1.Strong Entity,2.Weak Entity.The independent entity which posseses its own identifier and doesn't need another entity to work is a strong entity.On contrary, the entity whose function depends upon the other entities and it may only posses a partial identifier is known as weak entity. Part-III is another kind of E-R which is known as E-E-R(Enhanced Entity Relationship). (Thanx yushrah and ABK ) Last edited by Argus; Monday, April 11, 2005 at 09:23 PM. 
|




| The Following User Says Thank You to Argus For This Useful Post: | ||
syed amjad shah (Monday, April 28, 2008) | ||
|
#2
Monday, April 11, 2005
|
||||
|
||||
|
CGI refers Common Gateway Interface. It is one of the earliest scripting languages .a CGI application runs entirely on server,and can be used to create dynamic web applications. CGI programs are small executables, that the server executes in response to a request from a browser.it is most common application in the forms processing.CGI allows you to create pages for users as individual requests come in , and you can customize pages to match that information.
Perl : it is a language with powerfull text-processing capabillities.Perl is undoubtedly the most common language used for scripting CGI. i don't have any practical exposure abt perl that's why i m giving you some theoritical knowledge regarding this.the matter of the fact is that now CGI is loosing its market just because of its extra overhead on server and ISAPI is taking its place; well proceed further.. most of CGI is just standard Perl, with a few changes here and there . CGIs process input differently than old Perl scripting does - and this is the only difference you'll find between the two. Once the CGI scripts process the input, it becomes data, which is treated pretty much the same way by both CGI and Perl scripts. CGI input can be retrieved in two different ways: "get" and "post." Perl has allowed us to provide a very easy to use and enjoyable interface to our database servers. The servers are actually on NT running a proprietary database software package. The database software is very good at performing both full text and exact term searches of the term data. However, the software interface to the database engines is weak and unusable at best. By using Perl to talk to the database server's HTTP interface we were able to extract the desired results data and then use Perl's power to reformat the results into something pleasing and tailored to the user's preferences. we can write Perl script on texteditor.it is possible to write simple programs in Perl with minimum of effort. As we can write CGI programs in c++,c but perl is mostly preffered. Perl is a full fledged programming language.It was desgined with an objective to make dynamic and smart web pages. It has an extensive structure handling feature.Syntaxwise this language is short but its library makes it like C.I mean short but powerful.Here is an exaple: This is a program written in Perl which will take user input for two enteries and will add them, 1 print "Please Enter 1st no to add:\n";'\n is to move to the other line with out printing it, the messages doesn't matter how many times u use the print statement will print on the same line[like C]' 3 $number1=<STDIN>;'causes execution of the program whilw the computer is waiting for user input' 4 chomp $number1;'removes charecter/no from the ending of the line placed as the input[previous input](for new entry)'[I take this to be an ambiguity and should be removed by making its compiler powerful and understanding that a new input is supposed to be made so clear the previous input so that syntax becomes shorter like we do this in C] 6 print "Please enter second no:"; 8 $number2=<STDIN>; 10 chomp $number2; 13 $sum=$number1+$number2; print "The sum is $sum";'no need to express format type as the variable is scaler and is defined wherever need' Now that was a sample program.If I am asked to compare its syntax with some language.It would certainly be the Basic. Now a brief account of Perl's programming approach. Programs may be written in different ways and Perl is a highly portable language.Its code is easy to understand. Perl 3, 4 and 5 and 6 are the versions available in the market but Perl 6 is the latest in use.Perl 6 (2000)is a complete rewrite of internals and externals after complete re-organization of done in its previous version. (Thanx yushrah and ABK Jun 2002) Last edited by Argus; Monday, April 11, 2005 at 09:24 PM.
|
| The Following User Says Thank You to Argus For This Useful Post: | ||
Austere (Tuesday, June 19, 2012) | ||
|
#3
Monday, April 11, 2005
|
||||
|
||||
|
Computer languages are divided into two major classes. (1).Procedural Programming Languages and (2).Object Oriented programming Languages. Today we got to discuss the second class so let's start with it.
To understand Object Oriented Programming(Language) well, one should have good acquanitance with fundamental Programming techniques. The Programming Languages have divided the world into two parts. *Data and *Operations on Data. Data is static and is immutable unless affected by the certain operations which could certainly bring about a mutation in the structure of it(data). The operations which operate Data are called as procedures or functions. A point to understand here is that these functions or procedures which we pronounce as operations on data have no lasting state, they are only useful when they affect data in a desired fashion as that is the purpose of their life. Now being succinct I come straight to the main topic and will depict why to use OOPL? How much distinct it is intrinsically from the PPLs? answering first query; OOPLs provide the programmer with the following advantages which are not provided by the former class as it makes programs: 1. more intuitive to design 2. faster to develop 3. amenable to modifications 4. easier to understand 5. conceiving program tasks in a better way 6. more secure and easy to restrict 7. inherit from classes and to overload methods which could be run recursively and need to be defined once 8. get merged with other programs in such a way that no fear of data loss remains likely Second query is answered as so; Same functions and procedures used in PPLs are extended and re-organized in a novel way. Making it closer to the nature but yet has a drawback of the lack of elucidation which makes it harder to understand. It means that the OOPL(s) have the same state and behavior and a real high level unit called object to make the programming dynamic and faster. Now to define OOP, firstly one should learn what an object stands for? Object is everything and just a black box. This statement means that everything present on the suface of the planet is an object, while taking OOP as an ad hoc it is merely a box which has a function to receive and transmit data according to the signals or commands. Making it easier to understand I will put it this way. OOP is something which groups Data and Operations into modular units called Object. This object will receive signals in the form of command syntax will operate the data the way, it(code) is directing and then finally to bring the result back to the programmer alongwith the command control. Here we reach a conclusion and in a better postition to define OOP. "The insight of object-oriented programming is to combine state and behavior, data and operations on data, in a high-level unit, an object, and to give it the language support" Now a curt description of the Object Oriented Development Environment Basically this environment is comprised of three parts. 1. A library of objects, software frameworks and kits(for building GUI and other graphical applications). 2. A set of Development tools(Merging and modifying more than one programs etc) 3. An Object-Oriented Programming Language(Enabling a programmer to encode a program into the specified fashion, and making the system understand to work according the user needs and commands) Now some brief notation of the most important and frequently used OOP terms. 1. Object(defined earlier) 2. Message(Software objects communicate with each other via messages) 3. Class(A prototyped that defines the variables and methods common to all objects of the similar kind, thereby making program re-useable and extensible) 4. Inheritance(Provides a natural and powerful mechanism for organizing software programs, usually a class inherits state and behavior from its super-class) 5. Overloading(multiple declaration or assignment of a method) That was a brief introduction to the OOP(L). Any kind of supplementation has got full scope and will surely get a decent response. Ahmad Bilal Khan(Thanx ABK)
|
|
#4
Monday, April 11, 2005
|
||||
|
||||
|
Two of the more common data objects found in computer algorithms are stacks and queues.
Stacks are data structures, which maintain the order of last-in, first-out (LIFO) Queues are data structures, which maintain the order of first-in, first-out (FIFO) ***Stack: A stack is a storage device that stores information in such a way that the item stored last is the first item retrieved. A stack is an ordered list in which all insertions and deletions are made at one end, called the top. Stack Pointer: the register that holds the address for the stack is called a stack pointer (SP)coz its value always points at the top item in the stack. Operations of a Stack The operations of a stack can be matched to the stack of trays. The last tray placed on top of the stack is the first to be taken off. The two operations; performed on a stack are insertion and deletion of items.Insertion and deletion, both acted upon at one end of the list (called the top). · Push(X) Insert element with value X at top of stack. · Pop() Remove top element of stack These operations are simulated by incrementing or decrementing the stack pointer register. The PUSH operation is implemented with the following sequence of micro operations: SPß SP+1 (increment stack pointer) M [SP]ßDR (write item on top of the stack) If (SP=0) then (FULLß1) (check if stack is full) EMPTYß0 (Mark the stack not empty) The POP operation is implemented with the following sequence of micro operations: DRß M [SP] (Read item from the top of stack) SPßSP-1 (Decrement stack pointer) If (SP=0) then (EMPTYß1) (check if stack is empty) FULLß0 (Mark the stack is not full) Stack as an Abstract Data Type Here is a more formal definition of the stack ADT: A stack is a data structure containing zero or more elements, on which the following operations can be performed: create Create a new, empty stack object. empty Determine whether the stack is empty; return true if it is and false if it is not. Push and Pop I have defined earlier top Return the element at the top of the stack (without removing it from the stack). (This operation, too, can be performed only if the stack is not empty.) This abstract data type definition says nothing about how we will program the various stack operations; rather, it tells us how stacks can be used. We can infer some limitations on how we can use the data. A stack organization is very effective for evaluating arithmetic expressions. ***Queue: A queue is an ordered list in which all insertions take place at one end, the rear, while all deletions take place at the other end, the front. Like a line of people waiting for some service, a queue acquires new elements at one end (the rear of the queue) and releases old elements at the other (the front). Queues are more difficult to implement than stacks, because action happens at both ends. Queue as an Abstract Data Type Following is the abstract data type definition for queues, with the conventional names for the operations: · create Create a new, empty queue object. · empty Determine whether the queue is empty; return true if it is and false if it is not. · enqueue Add a new element at the rear of a queue. · dequeue Remove an element from the front of the queue and return it. (This operation cannot be performed if the queue is empty.) · front Return the element at the front of the queue (without removing it from the queue). (Again, this operation cannot be performed if the queue is empty.) Types of Queues : some of them are given below: Circular Queues :Circular queues let us reuse empty space. Double-ended queues - These are data structures which support both push and pop and enqueue/dequeue operations. Priority Queues(heaps) - Supports insertions and ``remove minimum'' operations which useful in simulations to maintain a queue of time events. this is what the brief account in context of stack and queries "Polish Notation and Stack Evaluation". There are some terminologies could help us a lot while writing down an essay over Stacks and Ques in exams like; infix, Polish or Parenthesis-free notation. Infix is the ordinary notation for writing expressions, where operators separate arguments. for example, 3+7 while in the case of Polish notation which is really useful for stack oriented evaluation operater comes after the arguments. for example, 3, 5, +(Polish notation) => 3+5 (infix notation) and 10 , 6, 9, *, + (Polish notation) => 10+(6*9) (infix notation)etc A polish expression could better be evaluated by such algorithm using two stacks. A polish stack will contain polish expression and the evaluation stack stores the intemediate values during execution. Lets evaluate the polish expressions now. We will use A, B and C to hold data. What will happen when the program will execute. The following actions will be done: 1. If the polish stack is empty, halt with the top e. stack as the answer. 2. If stack is not empty, pop the polish stack into A. 3. If A is a value then push A onto the e. stack. 4. If A is an operator then pop the e. stack twice, first into C and then into B. Then do the computation of B and C and then operate them on by A and push the result into e. stack. Go to step 1. That was a curt introduction to the evaluation of Stacks and what are polish notations (Thanx ABK and Yusshrah)
|
|
#5
Thursday, April 14, 2005
|
||||
|
||||
|
ASSALAMOALIKUM,
HOPE EVERYBODY IS DOING FINE BY GOD'S GRACE. I AM WRITING SOME SIMPLE MAIN DIFFERENCES B/W LAN AND WAN, HOPE IT WILL HELP .1)LAN is tied to a certain location(e.g within a building, office or a campus or even can span several buildings) and WIRELESS LAN is a high speed network that operates without the hassle of wires, further lANs are available as either BROADBAND(that uses analogue technology) or BASEBAND(that uses digital technology) systems, Where as WAN is not tied to a certain location . 2)LAN'S setup cost , relatively speaking is cheap so we can put an extra couple of network points or devices on the network , but WAN'S setup cost is expensive. 3)Since LAN channel is typically privately owned by the organization using the facility so it's more secure as compared to WAN , that is controlled by a large company serving millions. 4)In case of LAN ,besides file sharing hardware sharing is possible as well but in case of WAN hardware sharing is not possible. 5)In LAN , data rate is usually greater like Ethernet could run upto 1000 Mbs, where as WAN's data rate is slow about a 10th od lan's speed, since it involves increased distance and increased number of servers and terminals etc. 6)In case of LAN , error rate is less and it's much easier to manage LAN and to diagnose and remove errors as compared to WAN , where error rate is high and error removal and diagnosis is much difficult. 7)Traditionally, LANs make use of broadcast network approach/techniques rather than switching approach/techniques that are used by WANs.But now switched LANs (especially switched Ethernet LANs,ATM LANs and Fibre channel LANs have appeared.
|

|
#6
Thursday, April 28, 2005
|
|||
|
|||
|
Can someone please elborate about Pipelinning
 the book recommended is not well versed in it as far as past papers are concerned... the book recommended is not well versed in it as far as past papers are concerned...  Me awaiting a quick reply  eyes: eyes:
|
|
#7
Thursday, April 28, 2005
|
||||
|
||||
|
ASSALAMOALIKUM,
HOPE FRND U R FINE BY GOD'S GRACE.HOPE IT WORKS OUT FOR U.In computers, pipeline is a continuous and somewhat overlapped movement of steps of an instruction to the processor and pipelining is the use of a pipeline.It is a technology used on microprocessors ,particularly it's a standard feature in RISC(reduced instruction set computer) processors.A pipelined processor works on different steps of an instruction at the same time, so more instructions can be executed in a shorter period of time,thus enhancing their troughput and performance.Instructions consist of a number of steps. Practically every CPU ever manufactured is driven by a central clock. Each step requires at least one clock cycle. Each step of an instruction is performed by a different piece of hardware on the CPU. Early, non-pipelined, processors did only one step at a time. For example, they might perform these steps sequentially in order: Read the next instruction Read the operands, if any Execute the instruction Write the results back out This approach, while simple, is wasteful. While the processor is adding numbers, for instance, the hardware dedicated to loading data from computer memory is idle, waiting for the addition to complete.Pipelining improves performance by reducing the idle time of each piece of hardware. Pipelined CPUs include circuitry that examines the instructions and breaks them down into their sub-instructions. Some sub-instructions of different instructions can be executed simultaneously by different pieces of hardware, exploiting more parallelism in the hardware. A control unit called the pipeline controller ensures that this is done in a safe way that does not change the end result.For instance, a typical instruction to add two numbers might be ADD A, B, C, which adds the values found in memory locations A and B, and then puts the result in memory location C. In a pipelined processor the pipeline controller would break this into a series of instructions similar to: LOAD A, R1 LOAD B, R2 ADD R1, R2, R3 STORE R3, C LOAD next instruction The R locations are registers, temporary memory inside the CPU that is quick to access. The end result is the same, the numbers are added and the result placed in C, and the time taken to drive the addition to completion is no different from in the non-pipelined case.The key to understanding the advantage of pipelining is to consider what happens when this ADD instruction is "half-way done", at the ADD instruction for instance. At this point the circuitry responsible for loading data from memory is no longer being used, and would normally sit idle. In this case the pipeline controller fetches the next instruction from memory, and starts loading the data it needs into registers. That way when the ADD instruction is complete, the data needed for the next ADD is already loaded and ready to go. The overall effective speed of the machine can be greatly increased because no parts of the CPU sit idle. Each of the simple steps are usually called pipeline stages, in the example above the pipeline is three stages long, a loader, adder and storer. Every microprocessor manufactured today uses at least 2 stages of pipeline. (The Atmel AVR and the PIC microcontroller each have a 2 stage pipeline). Many designs include pipelines as long as 7, 10 and even 20 stages (like in the Intel Pentium 4). The Xelerator X10q has a pipeline more than a thousand stages long[1] .To better visualize the concept consider a theoretical 3-stages pipeline: Stage Description Load Read instruction from memory Execute Execute instruction Store Store result in memory and/or registers and a pseudo-code assembly listing to be executed: LOAD #40,A ; load 40 in A MOVE A,B ; copy A in B ADD #20,B ; add 20 to B STORE B, 0x300 ; store B into memory cell 0x300 This is how it would be executed: Clock 1 Load Execute Store LOAD The LOAD instruction is fetched from memory. Clock 2 Load Execute Store MOVE LOAD The LOAD instruction is executed, while the MOVE instruction is fetched from memory Clock 3 Load Execute Store ADD MOVE LOAD The LOAD instruction is in the Store stage, where its result (the number 40) will be stored in the register A. In the meantime, the MOVE instruction is being executed. Since it must move the contents of A into B, it must wait for the ending of the LOAD instruction. Clock 4 Load Execute Store STORE ADD MOVE The STORE instruction is loaded, while the MOVE instruction is finishing off and the ADD is calculating. And so on. sometimes, an instruction will depend on the result of another one (like MOVE example). In this case, a pipeline stall will happen, where a pipeline will stop, waiting for the offending instruction to finish before resuming work. The throughput of the processor is not changed: one instruction is executed every clock cycle. But actually every instruction has been worked on for many cycles before.The higher throughput of pipelines falls short when the executed code contains many branches: the processor cannot know where to read the next instruction, and must wait for the branch instruction to finish, leaving the pipeline behind it empty. After the branch is resolved, the next instruction has to travel all the way through the pipeline before its result becomes available and the processor appears to "work" again. Popular ways of solving this problem include branch prediction and branch predication.Here friend u can explain these 2 things a little as well.Because of the instruction pipeline, code that the processor loads will not immediately execute. Due to this, updates in the code very near the current location of execution may not take effect because they are already loaded into the Prefetch Input Queue. Instruction caches make this phenomenon even worse. This is only relevant to self-modifying programs such as operating systems.FURTHER AS AN EXAMPLE U CAN GIVE RISC PIPELINE http://cse.stanford.edu/class/sophom...ing/index.html U CAN VISIT THIS ABOVE LINK AND WRITE IT AS EXAMPLE, U R ALWAYS WELCOME TO ASK ANYTHING , GOOD LUCK TO ALL,
|
|
#8
Friday, April 29, 2005
|
|||
|
|||
|
WAS.
Hope that you are in superb mood and May Allah showers His blessing upon u. Thanks a lot for your time. I am really thankful for your such a detailed response. One thing is driving me crazy is in 2004 paper and is about how guassian elimination alogrithm is useful for parallelization Have you any idea how much depth the topic Introducation to Parallel processing + SISD and MIMD can cover.Is it necessary to cover Array processor e.t.c stuff as well  Which book is/was followed by you cuz I have no idea whether you have apperaed in CSS exams or planning to appear this year eyes: Wishing u all the best ... Take Care :p Last edited by AaminahAbrar; Friday, April 29, 2005 at 08:16 AM. Reason: Spellings
|
|
#9
Wednesday, May 27, 2009
|
||||
|
||||
|
Probably nothing has influenced our lives more in the past 50 years than the invention of the electronic computer. Today computers are nearly ubiquitous. They are in our homes, our cars, our microwaves, our cellular phones, and even in our toys. Tiny computers called microprocessors are responsible for controlling many of the common appliances that we use every day from the automatic coffee maker to the hi-fi VCR. One way to get a sense of the pervasive nature of modern computers is see how these machines are depicted in art. Click on the arrows below to browse through the computer art gallery. See if you can identify with any of these humorous depictions of how computers influence modern life.
Why is it that computers have become such an integral part of modern life? One answer to this question might be that computers are both flexible and efficient. Consider the first quality: flexibility. Computers are truly universal machines. Unlike other machines such as cars, can openers, or washing machines, computers can be used to solve a variety of problems. By simply changing the instructions that control the computer, these machines can be transformed from a video arcade to a word processor. In this module, we will examine the structure of a computer and discover why these machines can be so flexible. Now consider the second quality: efficiency. Computers are certainly efficient at tasks which require many mathematical calculations and tasks which can be expressed in the form of an algorithm. Of course, computers are not efficient at all tasks. No one has ever seen a computer plant a garden or write a novel. However, many common tasks are well suited to computers, and that is why we see such a variety of pictures in the computer art gallery above. In this module, we will also discover why computers are efficient calculators and why computers require tasks to be expressed as algorithms. By the end of this module, you should be able to do the following:
|

|
#10
Wednesday, May 27, 2009
|
||||
|
||||
|
The fundamental unit of data storage in a computer is called a bit or binary digit. A bit is similar to a two-way switch. Just like a switch has two states (off or on), a bit also has two states (0 or 1). Often these two states represent the values false or true and are implemented inside a computer by using a low voltage value or a high voltage value. Since bits provide the foundation for all data storage, it is not surprising that the binary number system is very important to computers. If you are unfamiliar with binary numbers, it would be a good idea to review this topic before continuing.
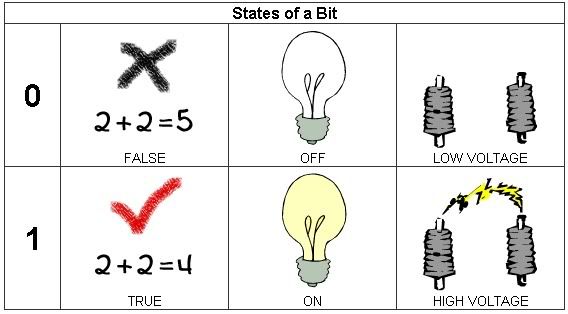 By themselves, bits are not very interesting or useful. In order to store more complex forms of data, bits are joined together into larger groups known as bytes. Every byte is made up of eight bits and can be used to encode data such as numbers (integers and reals) or character symbols. The most common scheme used to represent integers is called Two's Complement. Using this scheme, it is possible to represent the integers from -128 to +127. For real numbers, computers typically use a floating point representation similar to the one illustrated in the diagram below. With only eight bits, the range of real values that can be represented is very limited. To solve this problem, computers use two or more bytes when representing real numbers. Notice that the sixteen bits below are partitioned into three groups: the mantissa, the exponent, and two sign bits. This division allows the computer to represent floating point numbers such as .00947 in the binary equivalent of scientific notation. In this example, the mantissa (11101100112) corresponds to the decimal number 947 with a zero sign bit for positive value, and the exponent (00102) corresponds to 2, the power of ten, with a one sign bit for negative value. Notice that with 10 bits to represent the mantissa, this scheme only allows for 3 significant digits. We can also assign particular patterns of bits to represent common symbols such as letters, punctuation marks, and numerals. One very common representation of these symbols is ASCII, the American Standard Code for Information Interchange. The main memory of a computer is composed of millions of storage cells similar to the one illustrated in the applet. The size of the storage cells is known as the word size for the computer. In some computers, the word size is one byte while in other computers the word size is two, four, or even eight bytes. Each storage cell in main memory has a particular address which the computer can use for storing or retrieving data. This arrangement of cells is somewhat similar to a computer spreadsheet where each box of the spreadsheet can hold various data. Just like the boxes of the spreadsheet are identified by a row and column combination (e.g., A2, C4, etc.), the cells of a computer's main memory are identified by a particular address (e.g., Cell 1, Cell 2, etc.). The addresses begin at 0 and increase by 1 until the end of the main memory is reached. For simplicity, these addresses are shown below in decimal. However, in the computer, addressing is done using binary values. One important result of "organizing a machine's main memory as small, addressable cells is that each cell can be referenced, accessed, and modified individually. A memory cell with a low address is just as accessible as one with a high address. In turn, data stored in a machine's main memory is often referred to as random access memory (RAM)". Because computers have such large amounts of RAM, the size of the main memory is usually measured in megabytes (MB) rather than just bytes. One megabyte is equal to 220 bytes or 1,048,578 bytes. Some other common measures for quantities of bytes are listed in the table below. 
|



 |
«
Previous Thread
|
Next Thread
»
|
|

 Similar Threads
Similar Threads
|
||||
| Thread | Thread Starter | Forum | Replies | Last Post |
| WEb Building GLossary Terms | Janeeta | Computer Science | 3 | Monday, November 04, 2019 12:09 AM |
| EDS- notes | Predator | General Science Notes | 70 | Sunday, February 28, 2016 12:05 PM |
| Principles of Political Science | Xeric | Political Science | 8 | Friday, December 02, 2011 12:19 AM |
| Philosophy of Science | A Rehman Pal | Philosophy | 0 | Sunday, March 18, 2007 03:42 PM |

